Storage-Virtualisierung
Storage-Virtualisierung, naja was ist nun damit gemeint? Unter dem Thema Storage-Virtualisierung verstehen nicht immer alle das gleiche. Am Anfang meinte man unter Storage-Virtualisierung nur das simple „Mapping von physikalischen Laufwerken auf logische Volumes“, was nichts anderes war wie die RAID-Technologie mit einer flexiblen Partitionierung. Aber was ist nun heute alles neu wenn man über Storage-Virtualisierung spricht? Naja als wichtigsten Punkt könnte man die zentrale Verwaltung aller Storage-Komponenten sehen. Weiterhin könnte man hier die Features wie die Möglichkeit eines SnapShot nennen oder die Integration der Spiegelung und der Backups, ohne das hier Hardwarekomponenten diese Features unterstützen müssen. Über all diesen Punkten steht natürlich die zentrale Administration und Überwachung der gesamten Storage-Umgebung. Zudem rückt noch zu der reinen blockbasierten Virtualisierung der Storage-Umgebungen, die filebasierte Virtualisierung immer mehr in den Vordergrund.
Mittlerweile hat sich auch immer mehr der Begriff „Software Defined Storage“ (SDS) etabliert. Aber auch hier versteht man nicht immer das gleiche, was Ansätze und Begrifflichkeiten betrifft. Zu allererst was die zentrale Administration von herkömmlichen Storage-Systemen und deren direkte Anbindung in mögliche IT-Abläufe angeht. Weiterhin der Ansatz des Software-Based Storage, welcher mit der Bestückung von Servern mit Festplatten und der Installation einer Storage-Software auf dem Server, welche die Storage-Dienste bereitstellt, einhergeht.
Ansätze für die Virtualisierung
Eine dezentrale Virtualisierung wird direkt in den Storage-Devices, wie RAID-Controller und Switchen, realisiert. Zudem stellt jeder Hersteller Software und Tools zur Administration und Überwachung zur Verfügung. Über die bekannten gemeinsamen Schnittstellen, können diese Aufgaben dann direkt über Fibre Channel oder LAN erledigt werden. Solche Ansätze sind aus der Netzwerktechnik bekannt und Softwareprodukte wie HP-OpenView, CA Unicenter oder IBM NetView können hier integriert werden. Da heutzutage die Cloud und Servervirtualisierung immer stärker in den Mittelpunkt rücken, wird die Storage-Schicht auch immer stärker in die zentrale Verwaltung mit einbezogen (siehe Cloud-Dienste). Durch den Ansatz des „Software-Defined Storage“ wird somit ein gemeinsames Provisioning von Storage, Netzwerk bis hin zum Betriebssystem mit Anwendung ermöglicht. Die Verwaltung konventioneller Storage-Systeme über die angeschlossenen Applikationsserver ist ein weiterer Ansatz der Virtualisierung. Bei diesem Ansatz wird eine Softwareapplikation auf den Servern installiert, welche alle Verwaltungsaufgaben übernimmt. Alle Clients können dann über eine zentrale Console administriert werden. Diese drei aufgezeigten Ansätze sind aktuell die am meisten eingesetzten, wenn es um Storage-Virtualisierung geht. Wobei sich diese dann noch in 3 Gruppen, die „In-Band“-, „Out-Of-Band-Virtualisierung“ und lokale Virtualisierung aufteilen.
Verankerung der Virtualisierung im Storage-System
Diese Verankerung der Virtualisierung im Storage-System bedeutet das sämtliche Funktionen im Storage-System integriert sind. Somit ist kein zusätzlicher Server oder zusätzliche Hardware notwendig, dies bedeutet das die Verwaltung des reinen RAID-Systems und der Virtualisierung in einem einzigen Tool zusammengefasst sind. Dies bedeutet aber das sich ein wichtiger Ansatzpunkt der Storage-Virtualisierung nicht realisieren lässt, nämlich der Zusammenfassung mehrerer RAID-Systeme von unterschiedlichen Herstellern. Allerdings sind alle anderen Features realisierbar, sowie das Clustering dieser Lösung und das Aufteilen auf zwei unterschiedliche Standorte. Weil dieses Verfahren sehr nah mit der In-Band Virtualisierung verwandt ist, können hierbei auch zusätzliche Protokolle verwendet werden. Wobei dies natürlich abhängig ist von den unterschiedlichsten Herstellern. Da dieser Ansatz auch eine Verwandschaft mit dem Out-Of-Band Verfahren hat, hat diese Virtualisierung innerhalb des Storagesystems die beste Performance, da keine zusätzlichen Komponenten für die Administration des Datenstroms benötigt werden.
In-Band Virtualisierung
Bei der In-Band Virtualisierung agiert die Hard- und Software zur Virtualisierung direkt in den Datenpfaden zwischen den Servern und den Storage-Devices. Somit lassen sich sehr einfach weitere Protokolle für die Nutzung des Speichers integrieren. Dadurch ist auch die kostengünstige Nutzung von IP (FTP und Web), SMB und NFS möglich. Mit dieser Vermischung des NAS und SAN wird auch das Gesamtsystem viel flexibler und universeller. Ein Nachteil ist das Thema Ausfallsicherheit der Virtualisierungsschicht. Störungen oder Probleme in diesem Bereich führen zwangsläufig zum Totalausfall des SAN. Allerdings ist bei der In-Band Virtualisierung der große Vorteil die direkte Beeinflussung des Datenstroms ohne Umwege, dies ermöglicht auch die Realisierung eines „Serverless-Backups“.
Um die Performance nochmals etwas zu steigern können SSD- oder RAM-Speicher in die Virtualisierung mit eingebunden werden. Durch dieses Vorgehen lässt sich der Cache eines RAID-Controllers sehr kostengünstig von wenigen Gigabyte auf 100 oder mehr Gigabyte auch durch reinen RAM-Speicher aufrüsten. Mit der Einbindung schneller SSD’s lassen sich somit auch mehrere Terrabyte schnellen Speicher realisieren.
Diese Art der Lösungen, virtualisieren zum Storagesystem hin und realisieren die Freigaben über virtuelle Volumes zu den Servern hin. Man nennt diese Topologie auch „symmetrische Storage Virtualisierung“.

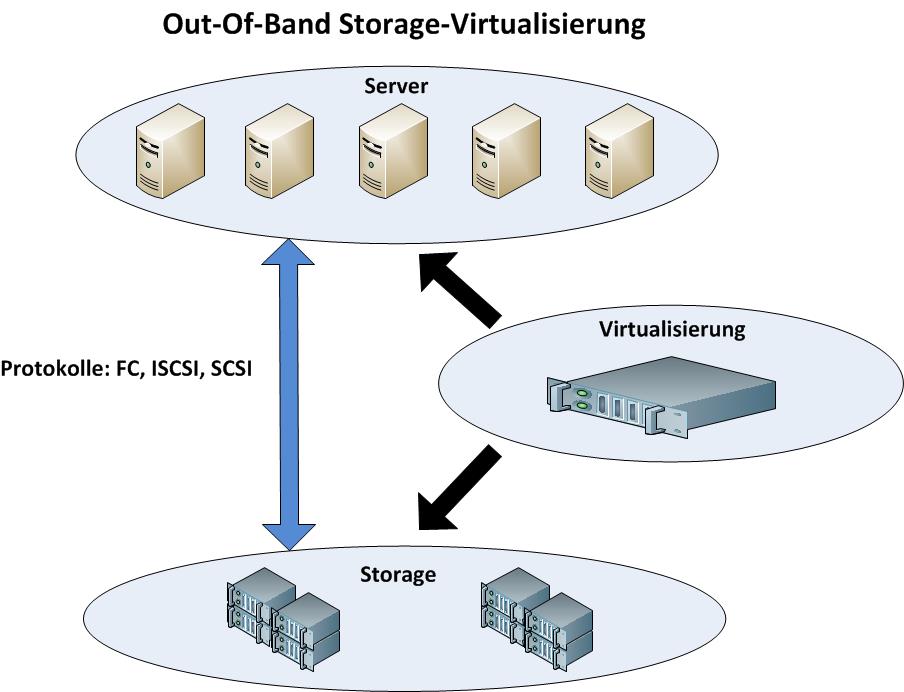
Out-Of-Band Virtualisierung
Bei der Out-Of_Band Virtualisierung agiert die Virtualisierungshardware (oder Software) neben dem Datenpfad. Fällt hier die Hard- oder Software aus, so stehen immer noch die Grundfunktionalitäten des SAN’s zur Verfügung. Allerdings können teilweise, je nach Virtualisierung, die Daten nicht mehr zugeordnet werden oder sind teilweise nicht verfügbar. Somit ist auch diese Technik nicht komplett gegen einen Ausfall automatisch gesichert. Wobei hier der Nachteil dieser Lösung klar auf der Beschränkung auf die üblichen Storage-Protokolle, wie FibreChannel, SAS und iSCSI liegt. Ein Ausbau auf die Protokolle NAS- und IP ist nicht so einfach möglich. In dieser Lösung werden die verfügbaren Ressourcen indirekt im Applikationsserver abgebildet. Dies geschieht entweder über eine spezielle Hardware im Host-Bus Adapter oder über eine Software-Schnittstelle. Im Zeitalter der Cloud-Technologien benutzt man diese Technologie um automatisch Speicher zuweisen zu können. Mittels eines User-Interfaces kann somit in der Cloud automatisiert ein Applikationsserver inkl. aller darunter liegender Technologien erstellt werden. Hierzu müssen Cloud-Software und Storage-System unbedingt kompatibel zueinander sein, damit die Cloud-Software das Storage-System auch administrieren kann. Die Cloud-Technologie ist ein Grund dafür das die Schnittstellen immer homogener werden und alles immer mehr zusammen wächst. Somit wird diese Art der Topologie auch „asymmetrische Virtualisierung genannt.
Software-Defined Storage (SDS)
Software-Defined Storage ist die neueste Technologie im Bereich der Storage-Virtualisierung. Die In-Band und die Out-of-Band Virtualisierung ist eigentlich auch eine Software-Virtualisierung. Hieraus haben sich auch die meisten Hersteller entwickelt, welche ganz neue Methoden aufzeigen. Der Hersteller VMWare hat z.B. das vSAN entwickelt. Innerhalb eines ESXi Servers wird ein Plattenpool aus SSD’s und SAS (und/oder NL-SAS Platten) gebildet. Wobei dieser Pool über einen Cluster von ESXi Servern (mindestens 3 Stück) gemeinsam gebildet und verteilt wird und die Daten über 2 oder mehr ESXi Server gespiegelt werden. Fällt nun eine Festplatte aus, so werden die gespiegelten Daten neu verteilt. Das Verfahren ähnelt sehr dem RAID 1 Verfahren, spiegelt aber die Daten zwischen Servern, also ein Software RAID. Die Datenverteilung erfolgt über Ethernet, wobei hier die Latenzzeiten genau beachtet werden sollten. Ein Nachteil der hierbei entsteht, ist das bei großen Datenmengen beim Ausfall eines Servers diese verlagert bzw. neu generiert werden müssen. Dies stellt eine extreme Belastung der Server dar, wenn dies in der Hauptbetriebszeit passiert.
Einige Vor- und Nachteile der Storage-Virtualisierung
Ein großer Vorteil der Storage-Virtualisierung ist die Verfügbarkeit der Lösung, allerdings nur wenn die Umgebung richtig designed wurde. Bei einem Ausfall der Virtualisierung kommt es ebenso zum Ausfall der gesamten Storage-Lösung, daher sollte die Virtualisierung möglichst hochverfügbar ausgelegt werden. Allerdings erhöht dies die Kosten enorm, da man auf geclusterte Lösungen zurückgreifen muss. Dies kann allerdings auch ein riesiger Vorteil sein, da durch eine einfache Spiegelung der Daten eine komplett hochverfügbare Lösung aufgebaut werden kann, welche automatisch mit allen Ausfallsszenarien umgehen kann. Das wichtigste bei HA-Lösungen ist allerdings die Aufteilung in 2 Brandabschnitte. Dies bedeutet die beiden Umgebungen sollten auch räumlich bei einem Brand von einander getrennt aufgebaut werden.
Wobei bei der Out-of-Band Virtualisierung ein weiteres Problem hinzukommt. Durch fehlende Standards in der Administration und Überwachung von Storage-Hardware, kann nicht jede Hardware von jeder Virtualisierungssoftware (oder Cloud Software) administriert werden. Aktuell gibt es nur Insellösungen, welche sich aber rasant weiter entwickeln.
Wann ist aber eine Virtualisierung möglich oder gar sinnvoll? Hier kommt es immer auf den Einzelfall an, wobei die Vorteile schon für sich sprechen. Durch eine Storage-Virtualisierung kann z.B. ein Mitarbeiter größere Mengen an Daten verwalten, da durch die Storage-Virtualisierung eine echte Konsolidierung der Daten über Hardwaregrenzen möglich ist. Sobald die eingesetzte Hardware unterstützt wird, ist auch der Schutz der Investition gegeben. Mit einer Storage-Virtualisierung können auch Protokolle wie iSCSI und NAS-Funktionalitäten im SAN abgebildet werden. Das Serverless Backup wird somit auch möglich. SnapShots und Spiegelungen lassen sich nun auch sehr flexibel integrieren.
Für eine Cloud-Umgebung ist die Integration der Storage-Hardware essentiell wichtig und notwendig. Somit bringt es z.B. wenig wenn sich ein Kunde einen virtuellen Server zusammenstellen kann, diesen auch starten kann, aber keinen Speicherplatz zugewiesen bekommt.
Hochverfügbarkeit bei der Storage-Virtualisierung
Die Virtualisierungs-Appliance ist die Grundlage für eine hochverfügbare Storage-Virtualisierungslösung, wobei sie die zentrale Verwaltung aller Speichersysteme ermöglicht. Für eine Hochverfügbarkeit wird diese Appliance als Cluster aufgebaut, wobei sie entweder als reiner Failover-Cluster (also eine Appliance stellt alle Dienste zur Verfügung die andere überwacht nur und übernimmt im Fehlerfall) oder als Lastenausgleichscluster (also beide Appliances übernehmen jeweils einen Teil der Dienste und überwachen sich gegenseitig) aufgebaut werden. Die Cluster sollten an unterschiedlichen Lokation (also in physikalisch getrennten Rechenzentren) aufgebaut werden (z.B. wegen Brandschutzmaßnahmen).
Ebenso sollten die beiden Storage-Systeme in physikalisch voneinander getrennten Rechenzentren aufgebaut werden, wobei eine Spiegelung (RAID 1) die Virtualisierung übernimmt. Somit sind die Daten immer redundant auf beiden Systemen vorhanden. Fällt ein Storage-System aus, kümmern sich die Virtualisierungs-Appliances ohne manuellen Eingriff um alles weitere.
Wurde dann auch noch die Netzwerk- sowie die Server-Infrastruktur redundant ausgelegt, könnte ein komplettes Rechenzentrum ausfallen und alle Anwendungen könnten somit problemlos weiter betrieben werden.
Stellt man dies in Verbindung mit einer Server-Virtualisierung hat man eine kostengünstige hochverfügbare IT-Lösung, welche sehr einfach zu administrieren und zu überwachen ist.

Konfigurationen innerhalb der Storage Virtualisierung
Innerhalb der Storage-Virtualisierung sind verschiedene Features der Konfiguration umsetzbar. Je nach Hersteller werden diese Features angeboten oder nicht und wenn sie angeboten werden, können diese Features von Hersteller zu Hersteller unterschiedlich konfigurierbar sein. Die nachfolgende Übersicht soll nur als Leitfaden dienen, wie diese Features im Detail umgesetzt werden, daher sollten diese auch jeweils individuell beim Hersteller überprüft werden.
Vertikale- und Horizontale Skalierbarkeit, sowie das Loadbalancing
Eine der schnellsten Möglichkeiten bei einem RAID-System den Plattenplatz zu erhöhen, ist dem Basisgerät weitere JBoD’s (Just a Bunch of Disks) hinzuzufügen. Diese Methode beherrscht nahezu jedes Gerät, sie wird auch vertikale Skalierbarkeit genannt. Der große Vorteil hier ist das JBoD’s einfach viel kostengünstiger sind als ein RAID-Grundsystem, da auch nur ein Basissystem überwacht werden muss. Der Nachteil hierbei ist das dieses Grundsystem in seiner Performance sehr eingeschränkt ist. Da dieser RAID-Controller nur einen gewissen Datendurchsatz hat und auch die Anbindung an ein SAN nur auf maximal 4 Ports funktioniert. Was bei 8Gbit/s Fibre Channel pro Port nur 32Gbit/s maximal wären.
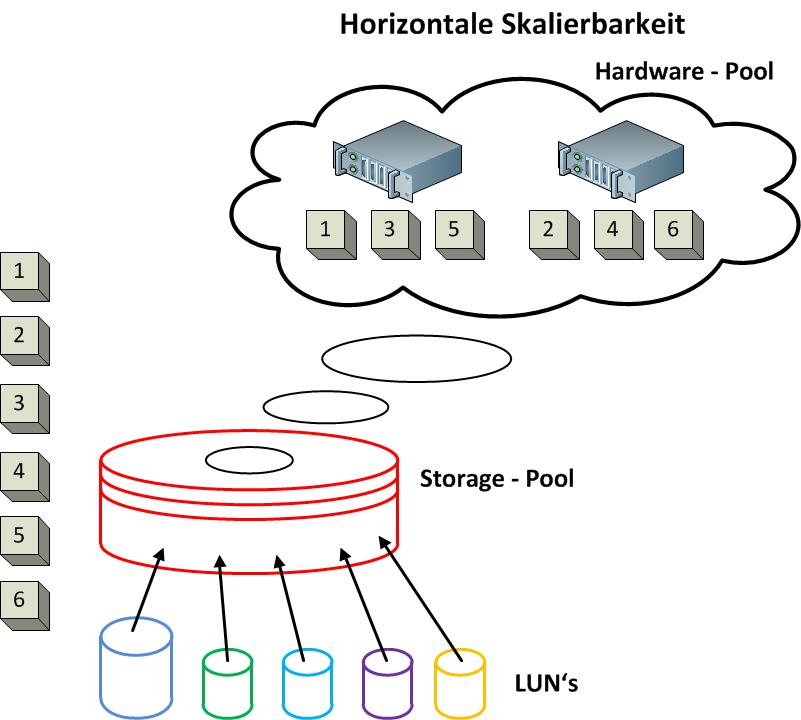
Die oben geschilderten Nachteile werden durch die horizontale Skalierbarkeit aufgehoben. Hierbei wird ein neues Grundsystem mit den bereits vorhanden Systemen kombiniert. Bereits vorhandene Volumes können auch über mehrere Grundsysteme verteilt werden, da jedes Grundsystem über eigene RAID-Controller verfügt und somit auch eigene SAN-Anschlüsse mit sich bringt. Dies steigert nicht nur die Kapazität sondern auch die Performance. Somit verfügen dann z.B. 4 eigenständige Grundsysteme mit je 4 Ports mit 8Gbit/s schon über insgesamt 128 Gbit/s Datendurchsatz zum SAN.
In dem unten stehenden Bild wird die horizontale Skalierbarkeit eines Storage-Systems dargestellt. Der gemeinsame Storage-Pool wird aus verschiedenen Grundgeräten gebildet, wobei die virtuelle Festplatte auf alle Grundsysteme verteilt wird. Ruft ein Server nun Daten von seiner virtuellen Festplatte ab, liefern beide Grundsysteme zur gleichen Zeit die Daten. Somit verdoppelt sich der Datendurchsatz nahezu. Diese doppelte Performance liegt natürlich auch beim Schreiben von Daten auf die beiden Systeme vor.
Für die Verteilung der Daten ist der Storage-Pool, also der Zusammenschluss der Grundgeräte, selbst zuständig. Somit wissen weder der Server noch das Betriebssystem hinter dem Storage-Pool von diesen Grundsystemen und bleibt auch transparent für alle weiteren Schichten. Muss nun ein weiteres Grundsystem in den vorhandenen Pool integriert werden, dann werden wiederum die Daten über alle System im Pool verteilt.
Thin Provisioning
Beim Thin Provisioning oder auch Over-Provisioning „gaukelt“ dies dem Betriebssystem viel Speicherplatz vor, wobei es dann allerdings nur den tatsächlich genutzten Speicherplatz auf den Festplatten belegt. Nun stellt sich die Frage warum denn dies alles?
Naja das ist ganz einfach zu beantworten. Bei der Einführung einer neuen Anwendung ist es oft so das man einfach nicht weiß wie viel Plattenplatz benötigt wird. Meistens wird immer ein bisschen mehr Plattenplatz genommen um in Sicherheit zu sein. Dies verschwendet meistens dann unnötigen Festplattenplatz oder man nimmt zu wenig was mit enormen Aufwand verbunden ist um dann den Plattenplatz zu erweitern. Daher wäre es doch fantastisch sagen zu können das das System immer so viel Speicherplatz bekommt das es immer ausreichend ist, wobei immer nur die Kapazität belegt wird die auch genau gebraucht wird. Somit sind alle Zufrieden gestellt, es gibt keine Plattenplatzprobleme mehr und es wird auch kein unnötiger Plattenplatz verschwendet.
Naja alles schön und gut aber wie funktioniert das denn nun? Legt ein Betriebssystem ein neues Filesystem an, ist dieses erst einmal nicht gefüllt. Es werden einzelne Blöcke belegt und auch Pointertabellen angelegt, welche sehr wenig Speicherplatz benötigen. Das Betriebssystem sieht also bei z.B. einer 1 TB Platte auch genau diese 1 TB in seinem Filesystem, wobei auf der Platte selbst nur wenige MB belegt sind. Werden nun Daten vom Betriebssystem in das Filesystem geschrieben, werden diese auch wirklich auf die Platte geschrieben. Aber der Plattenplatz des leeren Teils des Filesystems wird nicht genutzt. Sind also auf der virtuellen Platte von 1 TB nur 500 MB Daten und 2 MB an Filesysteminformationen, so sind auch nur 502 MB auf der Festplatte belegt. Beim Thin Provisioning muss natürlich der Plattenplatz auch immer überwacht werden. Werden z.B. auf einem RAID-System 10 virtuelle Platten zu je 1 TB angelegt und es sind aber nur 5 TB an Festplattenplatz vorhanden, wird es natürlich auch irgendwann einmal eng, wobei dies nur zentral auf dem RAID-System überwacht werden muss. Werden diese voreingestellten Grenzen überschritten wird eine Warnmeldung an den Administrator geschickt. Nun müssen zusätzliche Festplatten eingebaut werden. Dies kann mittels der vertikalen Skalierung geschehen oder es muss ein neues Grundsystem eingebaut werden, also eine horizontale Skalierung durchgeführt werden. Dies lässt sich alles auch im laufenden Betrieb durchführen.
Steigerung der Verfügbarkeit durch Replikation oder Spiegelung
Beide Verfahren unterscheiden sich in einigen wichtigen Punkten, sind aber trotzdem sehr ähnlich. Das Ziel beider Verfahren ist es die Daten an zwei unterschiedlichen Standorten zu speichern. Dies ist der typische Fall bei der K-Fall Vorsorge. Wird nun ein System oder Standort zerstört, kann unverzüglich bzw. mit sehr geringer Verzögerung wieder auf die Daten zugegriffen werden. Beim Replikationsverfahren wird mit einem Master-Slave-Verfahren gearbeitet, wobei der Master hier die I/O Anforderungen der Server annimmt und als Schreiboperation an den Slave weitergibt. Die synchrone Replikation gibt das Write-OK erst an den Server zurück, wenn die Daten beim Master und beim Slave angekommen sind, was natürlich zu leichten Verschlechterungen bei der Schreibperformance führt. Wobei aber die Daten immer auf beiden Systemen auf dem gleichen Stand sind. Es ist somit nach dem Start der synchronen Replikation kein manueller Eingriff mehr notwendig.
Das Write-OK wird bei der asynchronen Replikation an den Server zurück gegeben wenn die Daten schon beim Master angekommen sind, also ohne Zeitverzögerung. Die Daten werden dann in bestimmten Zeitintervallen vom Master zum Slave übertragen. Dies hat allerdings zum Nachteil das die Daten bei dieser Übertragung immer zu diesem Zeitpunkt konsistent sein müssen. Daher muss die Steuerung der asynchronen Replikation von den Servern gesteuert werden. Diese Art der Replikation ist zwar viel performanter, allerdings viel schwerer zu steuern und sehr aufwendig in der Steuerung.
Die Spiegelung liegt einem RAID 1 zugrunde. Hierbei werden die Daten gleichzeitig auf das eine wie auf das andere Storage-System geschrieben. Somit ist die Performance wie bei einem Einzelsystem. Allerdings ist das Verfahren der Spiegelung etwas aufwendiger zu realisieren, da fast immer eine sogenannte In-Band-Virtualisierung (siehe auch weiter oben zu diesem Thema) dazwischen geschaltet werden muss, welche das RAID 1 über die beiden Storage-Systeme übernimmt.
Tiering
Das Aufteilen der Daten auf verschiedene Medien, auch „Tiering“ genannt, ist sehr effektiv und flexibel in der Storage-Virtualisierung umsetzbar. Je nach Performance- und Verfügbarkeitsansprüchen werden beim Tiering die Daten auf unterschiedliche Plattensysteme geschrieben. Hierbei ist die Aufteilung auf verschiedene Plattentypen wie z.B. SSD, SAS oder SATA auch in einem RAID-System möglich. Ebenso kommt aber auch der gemeinsame Zugriff auf verschiedene RAID-Systeme bei der Storage-Virtualisierung zum Einsatz. Hierbei können die wichtigen performanten Daten auf Dual Controller-RAID Systemen abgelegt werden, wobei nicht so wichtige Daten auf SATA-Storages mit nur einem Single-Controller abgelegt werden können. Somit können z.B. Testsystemdaten von Produktionsdaten getrennt werden. Obwohl alle Server innerhalb der Storage-Virtualisierung auf alle Daten zugreifen können.
Somit kann z.B. ein Server auf alle Tiers des Storage-Systems zugreifen und seine Daten ablegen. Ein Datenbankserver kann z.B. seine Datenbankfiles auf dem Dual Controller Enterprise System ablegen, wobei er die Logs wiederum auf dem Single-Controller System mit SATA Platten ablegt.
Kurzes Fazit zum Thema Storage-Virtualisierung
Wie man aus den vorangegangenen Abschnitten ersehen kann ist eine professionelle Planung in diesem Bereich der Virtualisierung unerlässlich. Es ist hierbei sehr wichtig die geforderten Funktionalitäten und die vorhandene Hardware zu berücksichtigen, wobei hier jeder Hersteller in diesem bereich unterschiedliche Features anbietet, die man sich genauesten anschauen sollte, da diese enorm zum Erfolg des Projektes beitragen können.
Ihre Anforderungen, unser KnowHow
Die SYSM ist Ihr kompetenter Ansprechpartner wenn es um Storage-Virtualisierung Lösungen geht. Wir bieten Ihnen umfassende Dienstleistungen und Produkte für die Planung, Umsetzung und Betreuung rund um die Themen einer kompletten Storage-Virtualisierung Lösung an. Unser höchstes Ziel ist es den maximalen Mehrwert für Sie zu erzielen und somit gemeinsam Ihre Projekte zum Erfolg zu führen. Dafür stehen wir Ihnen mit unseren Storage-Virtualisierung Experten zur Verfügung.

Testen Sie unser KnowHow im Bereich Storage-Virtualisierung. Wir stellen Ihnen unsere Storage-Virtualisierung Experten gerne zur Verfügung.
Michael Schwab Geschäftsführer